HKUST SuperPOD is a state-of-the-art AI supercomputing facility. This system, being a University’s Central Research Facility (CRF), is now made available to all HKUST researchers to enhance their research capabilities related to AI. It serves as a platform to foster an "AI for Science" environment at HKUST.
Highlights
HKUST SuperPOD is a next-generation scalable infrastructure for AI leadership that provides the levels of computing performance required to solve advanced computational challenges in AI, high-performance computing (HPC), and hybrid applications where the two are combined to improve prediction performance and time-to-solution. It is a turnkey AI data center solution that provides world-class computing, software tools, expertise, and continuous innovation delivered seamlessly. The compute foundation of HKUST SuperPOD is built on NVIDIA DGX SuperPOD H800 systems, which provide unprecedented compute density, performance, and flexibility. The system is expected to be able to complete the massive AI tasks like GPT-3 training within an hour.
DGX SuperPOD is powered by several key NVIDIA technologies, including NVIDIA NDR (400 Gbps) InfiniBand, and NVIDIA NVLink technology, which connect GPUs at the NVLink layer to provide unprecedented performance for most demanding communication patterns. The DGX SuperPOD architecture is managed by NVIDIA solutions including NVIDIA Base Command, NVIDIA AI Enterprise, CUDA, and NVIDIA Magnum IO.
Photos and Diagrams
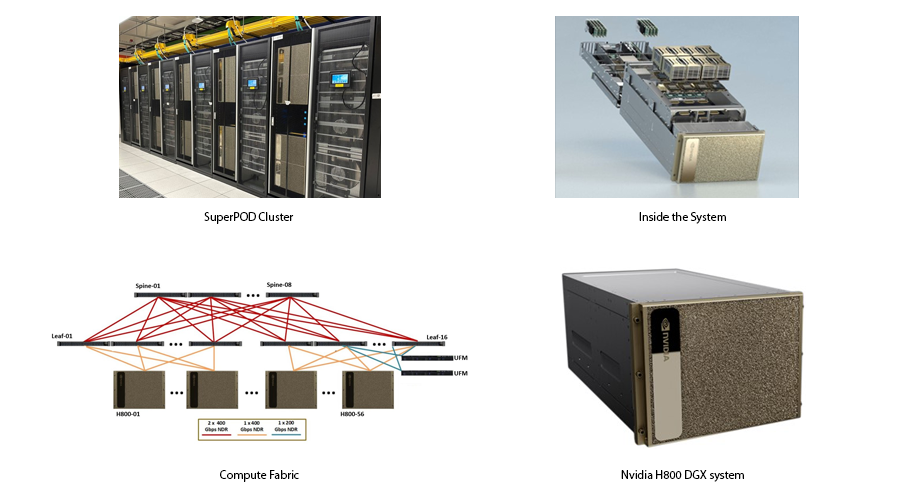
Click here to view enlarged photos and diagrams
Hardware Specification
For detailed hardware specification of the HKUST SuperPOD, please refer to this webpage.
Applicable Research Areas
The HKUST SuperPOD is specifically engineered to optimize performance for cutting-edge model training, with the capability to scale up to exaflops of computing power. It is designed to deliver the utmost performance in terms of storage as well. The HKUST SuperPOD serves a variety of use cases including AI research, LLM training, Transformer model development, and more. For comprehensive information on AI frameworks tailored to different research requirements, please refer to the AI Enterprise website.
Software List
Modules
Lmod is used to manage installations for most application software. With the modules system, user can set up the shell environment to give access to applications and make running and compiling software easier. It also allows us to run multiple versions of the same software that co-exist in the system with abstraction of version and high dependencies of the OS.
Click here for details on the module system.
NVIDIA AI Enterprise
It is an end-to-end, cloud-native software platform that accelerates data science pipelines and streamlines development and deployment of production-grade, GPU-optimized AI applications, including generative AI. Enterprises that run their businesses on AI rely on the security, support, and stability provided by NVIDIA AI Enterprise to ensure a smooth transition from pilot to production.

Click here for details on NVIDIA AI Enterprise
Use of Apptainer (Singularity)
Apptainer (formerly known as Singularity) container lets user run applications in a Linux environment of their choice. It encapsulates the operating system and the application stack into a single image file. One can modify, copy and transfer this file to any system has Apptainer installed and run as a user application by integrating the system native resources such as infiniband network, GPU/accelerators, and resource manager with the container. Apptainer literally enables BYOE (Bring-Your-Own-Environment) computing in the multi-tenant and shared HPC cluster.
Click here to view details of Apptainer (Singularity)
Workflow Examples
Some workflow examples can be found here for getting started in running jobs in HKUST SuperPOD.
Account Application
The HKUST SuperPOD account application is open to all HKUST faculty members who, as Principal Investigators (PIs), can apply for the necessary computing resources and accounts for their research projects. PIs are also responsible for resolving any expenses associated with the use of the HKUST SuperPOD system. For details, please visit the webpage "Charging for Use of HKUST SuperPOD".
Here is the link to apply for HKUST SuperPOD account. For enquiry, feel free to contact spodsupport@ust.hk.
HKUST SuperPOD also supports student learning purpose of instructor-led courses at their expense. Please contact the same email address for enquiry.
Getting Started
How to login to the cluster
Click here to view the instructions on how to get access to the HKUST SuperPOD cluster
Use of SLURM Job Scheduling System
The Simple Linux Utility for Resource Management (SLURM) is the resource management and job scheduling system of the cluster. All jobs in the cluster must be run with the SLURM.
Click here to learn how to submit your first SLURM job
Click here to view details of using SLURM
Partition and Resource Quota
Click here to view more information on partition and resource quota.
File and Storage
Click here to view more information on file and storage.
Job Priority and Scheduling
The Slurm scheduler works by applying a priority number to a job. To see all jobs with associated priorities one can use:
% squeue -o "%.10i %.8Q %.20j %.8u %.12a %.2t %.10M %.10L %R"
The priority number is continuously updated based on a number of factors, namely the length of time a job has been waiting in the queue, the number of GPUs requested and a fair-share algorithm.
- The longer a job waits in the queue, the higher priority is assigned.
- Large job that allocates multi-nodes resources has a higher priority in large project queue. This prevents large job from starving for required resource to start.
- The fair-share factor serves to prioritize queued jobs such that the jobs charging accounts that are under-serviced are scheduled first, while jobs charging accounts that are over-serviced are scheduled at a lower priority.
With all these factors into calculation of priority number, the slurm does not schedule jobs in a simple first-come first serve manner but this ensures a balance of sharing of SuperPOD resource for different type of jobs and users at a different usage pattern.
Nvidia GPU Cloud
Special Notes
Access guideline to student accounts for teaching course
Usage Tips
Best Practice
FAQ
Cluster Usage Status
Please refer to this webpage for the usage of HKUST SuperPOD (available soon)