The Simple Linux Utility for Resource Management (SLURM) serves as the designated resource management and job scheduling system within the cluster. It is mandatory for all jobs within the cluster to be executed through SLURM. To initiate a job or application, it is imperative to submit a job script to SLURM.
A SLURM script encompasses three essential aspects:
- Prescribing the resource requirements for the job: The script explicitly defines the necessary resources and specifications required for the successful execution of the job, such as CPU cores, memory allocation, time limits, and any other relevant constraints.
- Setting the environment: The script ensures the establishment of an appropriate and tailored execution environment for the job by configuring variables, module dependencies, paths, and other relevant settings necessary for seamless execution.
- Specifying the work to be carried out: The script outlines the specific tasks and procedures to be executed in the form of shell commands. It provides a clear and concise set of instructions that guide the execution of the job, enabling the system to carry out the desired computational operations and produce the intended results.
The most common operations with SLURM are:
| Purpose | Command |
|---|---|
| To check what queues (partitions) are available: | sinfo |
| To submit job: | sbatch <your_job_script> |
| To view the queue status: | squeue |
| To view the queue status of your job: | squeue -u $USER |
| To cancel a running or pending job: | scancel <your_slurm_jobid> |
| To view detailed information of your job: | scontrol show job <your_slurm_jobid> |
Use case example (Simple python job)
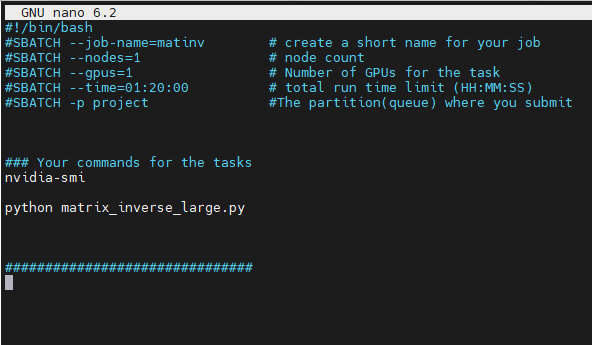
- The first line of a Slurm script specifies the Unix shell to be used.
- This is followed by a series of #SBATCH directives which set the resource requirements and other parameters of the job.
- The necessary changes to the environment are made by loading the anaconda3 environment module.
- Lastly, the work to be done, which is the execution of a Python script, is specified in the final line.
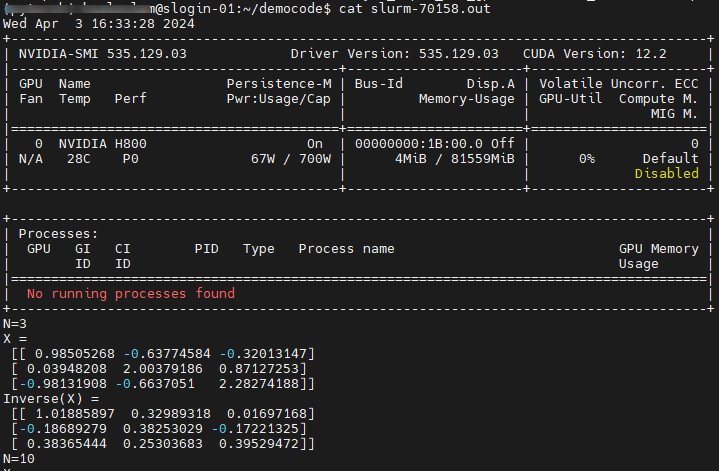
- Run sbatch to submit job
- "squeue -u netid" enable user to check job status

- Use "cat" to print output from slurm-jobid.out
- You may download the following tools for Job script generation generator(https://github.com/BYUHPC/BYUJobScriptGenerator.git)
Slurm script examples
Example 1: create a slurm script to run 2 applications (each application can use 2 CPU cores and 1 GPU device) in parallel.
#!/bin/bash # NOTE: Lines starting with "#SBATCH" are valid SLURM commands or statements, # while those starting with "#" and "##SBATCH" are comments. Uncomment # "##SBATCH" line means to remove one # and start with #SBATCH to be a # SLURM command or statement. #SBATCH -J slurm_job #Slurm job name # Set the maximum runtime, uncomment if you need it ##SBATCH -t 48:00:00 #Maximum runtime of 48 hours # Enable email notificaitons when job begins and ends, uncomment if you need it ##SBATCH --mail-user=user_name@ust.hk #Update your email address ##SBATCH --mail-type=begin ##SBATCH --mail-type=end # Choose partition (queue) with "gpu" #SBATCH -p <partition_to_use> # To use 4 cpu cores and 2 gpu devices in a node #SBATCH -N 1 -n 4 --gres=gpu:2 # Setup runtime environment if necessary # or you can source ~/.bashrc or ~/.bash_profile # Go to the job submission directory and run your application cd $HOME/apps/slurm # Execute applications in parallel srun -n 2 --gres=gpu:1 myapp1 & # Assign 2 CPU cores and 1 GPU device to run application "myapp1" srun -n 2 --gres=gpu:1 myapp2 # Similarly, assign 2 CPU cores and 1 GPU device to run application "myapp2" wait
Example 2: create a slurm script for a GPU application.
#!/bin/bash # NOTE: Lines starting with "#SBATCH" are valid SLURM commands or statements, # while those starting with "#" and "##SBATCH" are comments. Uncomment # "##SBATCH" line means to remove one # and start with #SBATCH to be a # SLURM command or statement. #SBATCH -J slurm_job #Slurm job name # Set the maximum runtime, uncomment if you need it ##SBATCH -t 48:00:00 #Maximum runtime of 48 hours # Enable email notificaitons when job begins and ends, uncomment if you need it ##SBATCH --mail-user=user_name@ust.hk #Update your email address ##SBATCH --mail-type=begin ##SBATCH --mail-type=end # Choose partition (queue) with "gpu" #SBATCH -p <partition_to_use> # To use 24 cpu core and 4 gpu devices in a node, uncomment the statement below #SBATCH -N 1 -n 24 --gres=gpu:4 # Setup runtime environment if necessary # Or you can source ~/.bashrc or ~/.bash_profile source ~/.bash_profile # Go to the job submission directory and run your application cd $HOME/apps/slurm ./your_gpu_application
Interactive job
The basic procedure is:
- Log in to a HPC machine
- Request compute resources using srun, salloc, or similar
For example:
srun --partition project --account=itscspod --nodes=1 --gpus-per-node=2 --time 0-01:00:00 --pty bash
- Start your program and get port information.
- ssh into the compute node you got using a login node as a jump host and forward the appropriate port.
Check the Workflow example page for details.
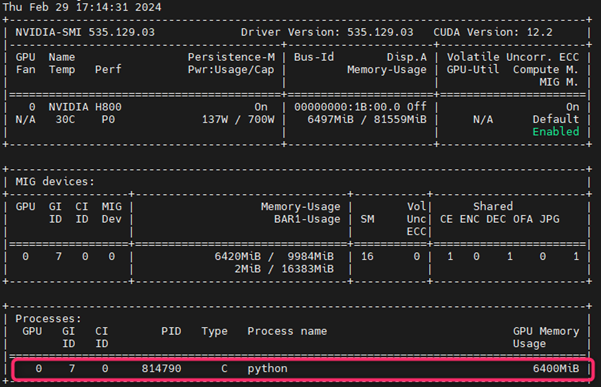
Check GPU usage for the job
Type this command:
srun --jobid=xxxxx -w dgx-xx --overlap --pty bash -i
replace the jobid and the name of compute node you want to check

References:
- https://wiki.rc.usf.edu/index.php/SLURM_Interactive
- https://github.com/SouthernMethodistUniversity/hpc_docs/blob/main/docs/access.md